We discuss in this article the use of containers for running AI and ML applications and why these applications might benefit from sharing access to remote and partial GPUs with VMware vSphere Bitfusion. The bulk of this blog, however, will be a detailed example of how to run a TensorFlow application in a containerized Bitfusion environment with remote GPU access.
Why Artificial May be the Real Thing
Artificial Intelligence and Machine Learning (AI/ML) applications are proliferating at an extraordinary rate because of their potential to perform “mental” tasks that traditional computation could not do well. They automate, at low cost, tasks that only people could perform before, not to mention tasks that could not be done at all. They may do these tasks with greater speed, consistency, and with no fatigue. If you need a general-purpose description, AI/ML works by throwing large collections of data (images, financial records, email chains or other text, statistical data on freeway traffic, etc., etc.) into the maw of statistical other computational models that gradually learn, “by themselves,” to identify trends and patterns in that type of data.
AI/ML applications make new products and services possible and make existing products and services better. Companies pursue AI/ML so they can be first to market and for fear of being left behind. Let’s list just a very few examples, let you draw your own conclusions, and leave it there.
Table 1: examples where AI/ML apps show results or promise
| Consumer |
Corporate |
| Spam filters |
Fraud detection |
| Malware protection |
Inventory |
| Traffic navigation |
Shipping |
| Facial recognition (e.g. social media photos) |
Customer support |
| Product recommendations |
Sales and market opportunities |
| Personal digital assistants |
Search engine refinement |
You’ll probably note that the division between the consumer and corporate apps is not that sharp.
The Container Challenge
What’s the deal with containers? They are part of that landscape that supports “modern apps”. The modern app, definitionally, can be a little fuzzy, but from a certain perspective you can think of it as just a list of demands that must be fulfilled so the app can keep its company from bankruptcy. It must run somewhere where it can be updated all the time. It must be broken into modular microservices (for modular testing, to isolate issues, to support frequent changes, to increase performance through concurrency). It must be fault tolerant. Each microservice must be written in the language and environment best suited for itself. It must be high-quality. This list goes on.
Containers help meet those demands. For example:
- Each microservice runs its own container, with each container providing the unique system libraries, code, and tools that that service needs
- Containers are lightweight; they do not consume the memory and compute power of a full OS or VM, so you can run more of them on a given set of hardware
- They boot up instantaneously (to us humans, anyway—we are told time does elapse); making it easy (or easier) to kill and relaunch any service gone rogue, to launch new instances in response to demand, and to invisibly roll out updates.
- They let you move the apps and services from place to place, from development to test to production. From private cloud to public cloud. But to the code running inside, nothing changes. You must work hard to introduce new problems and issues.
The Most Original Software Ever in the Whole Wide World
Since AI/ML is a new type of application, we should look at its requirements and make sure we can meet them. There are two requirements we are considering here.
You will likely want to run your app in containers. AI/ML applications often fall into the modern app camp. They interface with many other services all needing unique environments. Non-uniformity might be their call sign: non-uniform library dependencies for different models, non-uniform language requirements, non-uniform GPU requirements, non-uniform traffic, non-uniform scaling requirements. They may need to loop through training and inference at high frequency.
You will likely want to use hardware acceleration (a GPU, typically) to run your AI/ML application. The amount of computation to run these applications is one, two, or more orders of magnitude greater than traditional ones. An application running on a CPU might take an hour of time to do what you can do in 10 seconds on a GPU. Think of running thousands and thousands of operations on every pixel of thousands and thousands of high-definition pictures to get an idea of the scale. GPUs can perform the necessary type of math on hundreds of highly parallel cores. GPUs scale those orders of magnitude back down into a useful time domain.
Fortunately, it is easy enough to meet both of these requirements at the same time. You can buy GPUs, employ the software switches to pass them into container, and hand them over to the app running within.
But there is always one last requirement. Money.
Bitfusion Gives you Wings
GPUs have traditionally been difficult to share. As a piece of hardware sitting on a bus, only the software running local to that bus has been able to access it. If you move the software, you lose access. Even worse, two virtual machines, both running locally to a GPU, cannot share it. A GPU must be passed exclusively to one VM or the other. Compounding that, a single user, VM, or application seldom uses the GPU efficiently. It is not atypical for GPUs to sit idle 85% of the time. The industry average on this is hard to obtain, and it varies a lot from use-case to use-case. But if the price of a GPU seems high, it seems even higher when it is underutilized to this extent.
Enter VMware vSphere Bitfusion. It lets you share GPUs in two ways. Bitfusion sets up a pool of GPU servers, and gives GPU access, remotely, across the network, to applications or microservices running on client VMs or containers set up for each piece of software. GPUs, over the course of time, can “fly” from one application to another, being allocated and deallocated dynamically whenever an application needs hardware acceleration. Bitfusion also partitions GPUs into fractions of arbitrary size (it is the GPU memory that is partitioned), so the GPU can be used concurrently by multiple applications. All this raises the utilization and efficiency of the precious GPU resources.
These types of sharing address not only modern apps and acceleration requirements, but cost concerns too. You get to eat your cake, have it too, and give your sister a slice of her own.
The Brew that is True
![]()
At this point you are either itching to run an ML app in a container with Bitfusion or wondering how you ended up in an alternate universe reading a blog you are sure you already stopped perusing (if the latter, take the time, instead, to see if the humor in a 64 year-old movie holds up). So here is the fastest recipe we know to run a containerized TensorFlow benchmark using remote GPUs with Bitfusion. We will assume you have already followed the Bitfusion Installation Guide and created a Bitfusion cluster. (At the time of this writing Bitfusion is just a few weeks from release, and the example below will use beta code)
This recipe uses an NGC base image from NVIDIA. The NGC image comes with most of the software you need, has ensured the software versions are mutually compatible, and has tested everything for stability and completeness. The additional steps you need to take for Bitfusion are few.
We will use the TensorFlow_Release_19.03 NGC image. Its major components are Ubuntu 16.04, CUDA 10.1, and TensorFlow 1.13.0. For complete details see https://docs.nvidia.com/deeplearning/frameworks/tensorflow-release-notes/rel_19.03.html#rel__19.03.
The goal here is to run a containerized ML application (TensorFlow) using virtual GPUs provided by Bitfusion. The major steps are:
- Enable the Client VM to use Bitfusion
- Install the Bitfusion client software in the container
- Install the ML application (we’ll use the public TensorFlow benchmarks)
- In the container, use Bitfusion to run the ML application
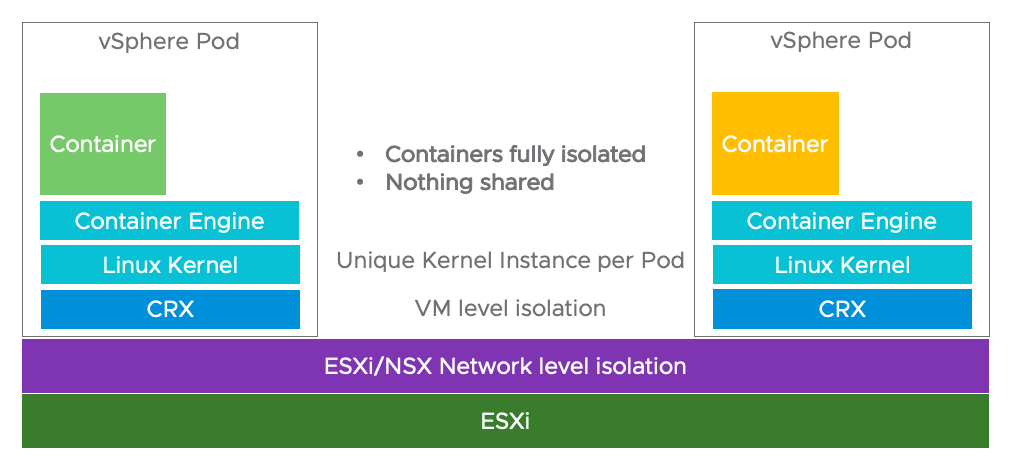
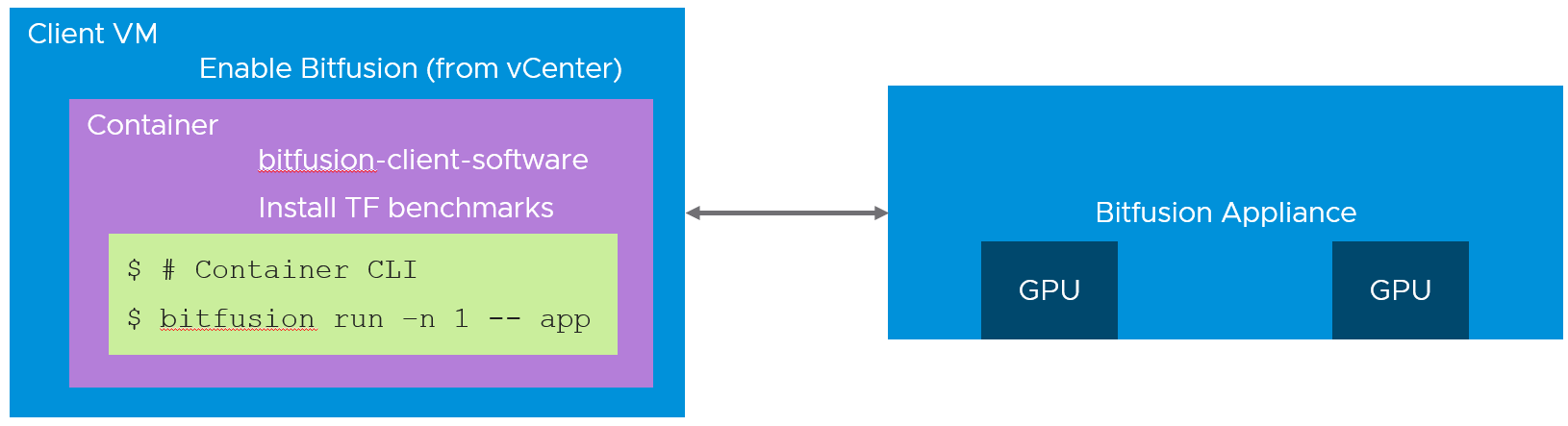
![Image showing the nesting of a Bitfusion container in a VM and also the Bitfusion server]()
Figure 1: Bitfusion nested in container
For the sake of completeness, this document will also show how to install Docker, but we encourage you to visit the Docker website if you want the latest, official instructions.
The process demonstrated here will use a Dockerfile to create the container. You can follow the steps in the Dockerfile to do it by hand if that allows you to explore or modify the process for your situation.
The Dockerfile assumes the existence in your current directory of the Bitfusion client deb package (for Ubuntu 16.04).
1. Enable Bitfusion
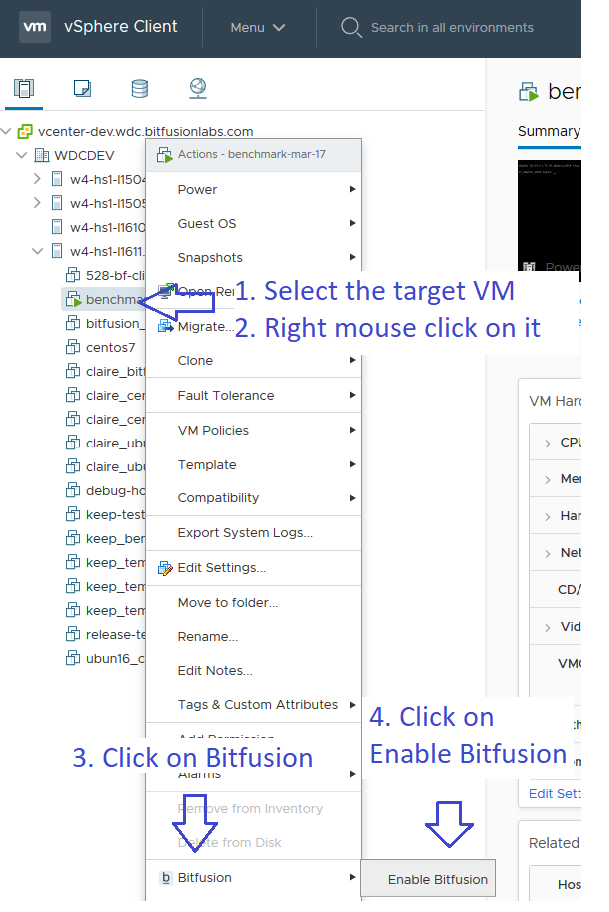
Use vCenter to configure and authorize the client VM where you will run your container:
- In vCenter on the “Hosts and Clusters” view, select client VM (where you will run your container)
rightclick → Bitfusion → select “Enable Bitfusion”
In the dialog box, confirm with the “Enable” button
![Image showing how to enable a Bitfusion client]()
Figure 2: Enable Bitfusion for client VM
2. Install Docker
Bitfusion runs on Ubuntu 16.04 and 18.04 and on CentOS 7 and RHEL 7 distributions. Below are instructions for installing docker. See the Docker website for details and official guidance.
A. Ubuntu
sudo apt-get update
sudo apt-get install -y docker.io
sudo systemctl start docker
# Make docker start on every reboot
sudo systemctl enable docker
sudo docker run hello-world
docker version
# Reports version 19.03.6 at this writing
B. CentOS and RHEL
# On CentOS you may need to install epel as a pre-requisite?
# sudo yum install -y epel-release
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
sudo yum check-update
sudo yum install -y docker-ce docker-ce-cli containerd.io
sudo systemctl start docker
# Make docker start on every reboot
sudo systemctl enable docker
sudo docker run hello-world
docker version # Reports 19.03.8 at this writing
3. Examine the Dockerfile
In one directory have two files. At this writing the Bitfusion package can be obtained from the VMware Bitfusion beta community site. After GA, packages will be available at a repository:
- bitfusion-client-ubuntu1604_2.0.0beta5-11_amd64.deb
- The Dockerfile (shown further below)
Here is the Dockerfile.
FROM nvcr.io/nvidia/tensorflow:19.03-py3
MAINTAINER James Brogan <someone@somewhere.com>
# Set initial working directory
WORKDIR /home/bitfusion/downloads/
# Update package list
RUN apt-get update
# Install Bitfusion. Assumes deb for Ubuntu16.04
# resides in mounted directory, /pkgs
COPY bitfusion-client-ubuntu1604_2.0.0beta5-11_amd64.deb .
RUN apt-get install -y ./bitfusion-client-ubuntu1604_2.0.0beta5-11_amd64.deb
# Must run list_gpus to pull in env and tokens
RUN bitfusion list_gpus
# TF benchmarks
WORKDIR /home/bitfusion/
RUN git clone https://github.com/tensorflow/benchmarks.git
# Set working directory
WORKDIR /home/bitfusion/benchmarks/
RUN git checkout cnn_tf_v1.13_compatible
# Set working directory
WORKDIR /home/bitfusion/
Points to note:
- Creates a container from NVIDIA’s NGC base image, tensorflow:19.03-py3
- Installs the Bitfusion client software and tests its list_gpus command (this will also initialize the tokens and certificates needed to communicate with the Bitfusion servers)
- Installs TensorFlow benchmarks from a public repo and checks out a compatible branch
4. Build the Image and Container
Below are two Docker commands. The first command builds an image we name, bfbeta-ngc1903-ub16-tf1-13. The second command, run, will give you a command line in the container instance of this image. The run command mounts two host directories in the container:
- /data – this directory contains a data set of images. You may or may not have a similar dataset available to you.
- /dev/log – this directory is not required, but is one means of avoiding warnings you’ll otherwise see when Bitfusion, inside the container, is prevented from logging to the syslog.
# The Docker build will take a couple of minutes, but only the first time
sudo docker build -t bfbeta-ngc1903-ub16-tf1-13 .
sudo docker run --rm --privileged --pid=host --ipc=host \
--net=host -it \
-v /data:/data \
-v /dev/log:/dev/log \
bfbeta-ngc1903-ub16-tf1-13
5. Run TensorFlow Benchmarks
After the previous step, your prompt will be inside the container and you will be root.
Now you can run TensorFlow benchmarks, invoking them directly or with convenience scripts. Two commands are show below, one assumes you have a data set, while the second uses synthesized data. Note: the bitfusion run command uses the -n 1 option to allocate 1 remote GPU for the benchmark, thus matching the number of GPUs that the benchmark itself expects to use due to its option, –num_gpus=1.
cd /home/bitfusion
# TensorFlow benchmark assuming an imagenet dataset
bitfusion run -n 1 -- python3 \
./benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--data_format=NCHW \
--batch_size=64 \
--model=resnet50 \
--variable_update=replicated \
--local_parameter_device=gpu \
--nodistortions \
--num_gpus=1 \
--num_batches=100 \
--data_dir=/data \
--data_name=imagenet \
--use_fp16=False
# TensorFlow benchmark with no dataset (use synthesized data)
bitfusion run -n 1 -- python3 \
./benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py \
--data_format=NCHW \
--batch_size=64 \
--model=resnet50 \
--variable_update=replicated \
--local_parameter_device=gpu \
--nodistortions \
--um_gpus=1 \
--num_batches=100 \
--use_fp16=False
Obey your Wurst
Going against the best advice, everyone eventually asks, “What’s in the sausage?” In this case, the caution seems unwarranted. We’ve seen a wholesome mix of technologies stuffed in a wrapper of low-denomination bills. We can run a modern ML application, we can run it in the environment made for it—containers—plus, we can run it with hardware acceleration. And vSphere Bitfusion delivers this mix with shared GPUs, making everything very affordable and efficient. We also note that the steps to do this, or the Dockerfile to set this up, are simple and minimal.
The post AI/ML, vSphere Bitfusion, and Docker Containers—A Sparkling Refreshment for Modern Apps appeared first on VMware vSphere Blog.