![]() I have wanted to write about the importance of isolation & segmentation in IT infrastructure for a while now, but with everything going on this year it felt like it would be redundant. However, over the last few months there have been several high-severity, high-profile CVEs (some ours, some others, and some in hardware, too) that are really shining a spotlight on the need to design IT infrastructure with more isolation in mind.
I have wanted to write about the importance of isolation & segmentation in IT infrastructure for a while now, but with everything going on this year it felt like it would be redundant. However, over the last few months there have been several high-severity, high-profile CVEs (some ours, some others, and some in hardware, too) that are really shining a spotlight on the need to design IT infrastructure with more isolation in mind.
Before we get in real deep I’d like to start at the beginning. What do I mean when I say “isolation?” I like to start with the Principle of Least Privilege, which is the idea that a user or application should only have the privileges on a system that are essential for them to complete their intended function. In practice we often think of it as not giving people root or administrator rights on a system and using the permission models to give them rights to what they need to access. One privilege is the ability to access management interfaces on computer systems, and in general, people in an organization who are not system administrators do not need access to those interfaces. As such, we isolate them so that we can add controls like firewalls & ACLs as a security boundary. Should a desktop in your organization be compromised by malware, the attacker would need to do considerably more work to access infrastructure that has been isolated in this way.
The other information security principle that factors in here is called “Defense in Depth.” Defense in depth is the idea that multiple overlapping layers of security controls are used throughout an organization so that if one fails or is temporarily weakened the organization is not left defenseless. We can implement network-based firewalls to control access to our organization at a high level, and then use NSX-T to add very granular rules at the VM level to provide additional coverage should an attacker make it past the outer defenses. Should an attacker make it past those, too, we practice good account hygiene and have strong passwords or multi-factor authentication to prevent them from logging in. We patch our guest operating systems and applications so we don’t give attackers opportunities there, and we also send our logs out to a log collection & reporting tool like vRealize Log Insight which can alert us to failed authentication attempts and allow us to act. With all these levels of protection, when a vulnerability is discovered we are often afforded some time to fix it, because we can rely on the other defenses to cover us for a bit until we’re back at full strength. That is defense in depth.
All that said, adding isolation is to add separations between the components of an IT infrastructure so that we can add security controls to them more granularly, prevent people who don’t need access from having access (insider threats), and add layers to our defenses to slow down and counteract breaches that may occur.
Ways to Add Isolation to vSphere
Isolation in our infrastructure comes in many different forms. One form is the protections that CPUs and compute hardware provide so that one VM cannot snoop on what another VM is doing. CPU vulnerabilities over the last few years have demonstrated gaps in that, and have been mitigated with new hardware firmware and software techniques (see “Which vSphere CPU Scheduler to Choose” for more information on what vSphere offers to help this on vulnerable hardware). Patching your system firmware is a huge step toward resolving these types of issues, as well as other issues affecting hardware management.
Another form is where there are clearly defined boundaries between systems. Authentication and authorization are good examples of this. Organizations often rely on Microsoft Active Directory for their authentication, providing benefits for single sign-on and central account management. However, you lose isolation between the systems when you use Active Directory for authorization, too. Someone with privileges in Active Directory can affect who can access other parts of infrastructure, even if they’re not authorized to. This is most often seen where organizations use an Active Directory group to control access to vCenter Server. To add isolation between vSphere and Active Directory use a vSphere SSO group instead, adding Active Directory accounts to it. This way you still keep single sign-on and centralized control, but an attacker who gains access to Active Directory cannot simply add themselves to vSphere and log in. To compromise vSphere they will have to do more work to find and compromise a vSphere Admin’s account, which increases the odds their actions will be noticed by you!
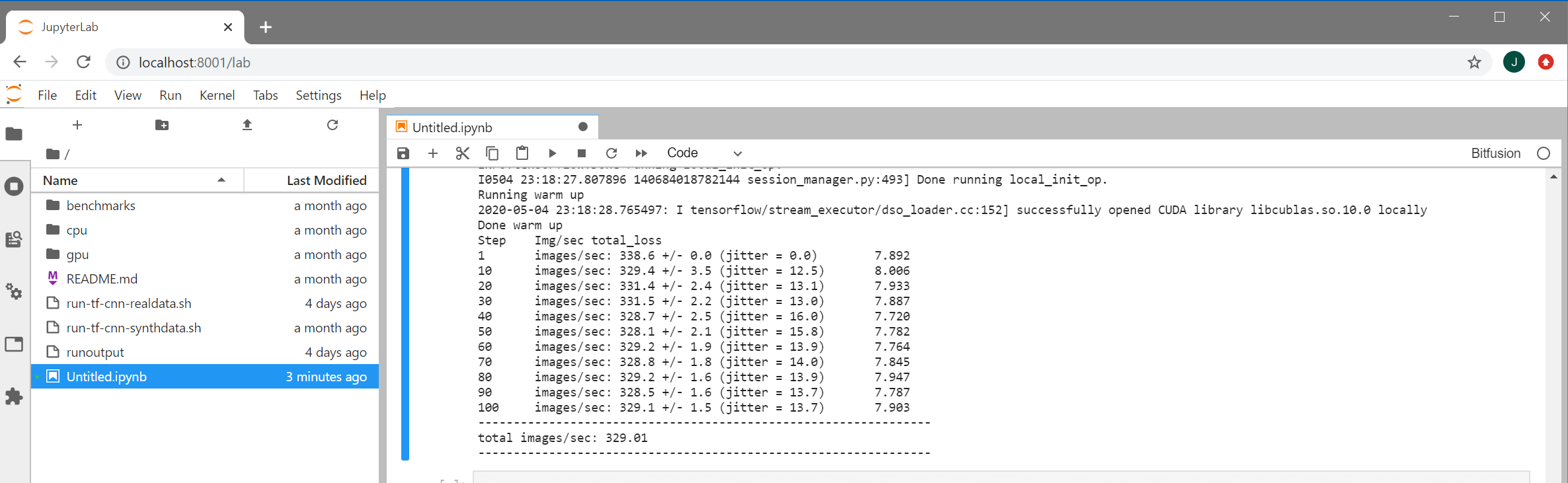
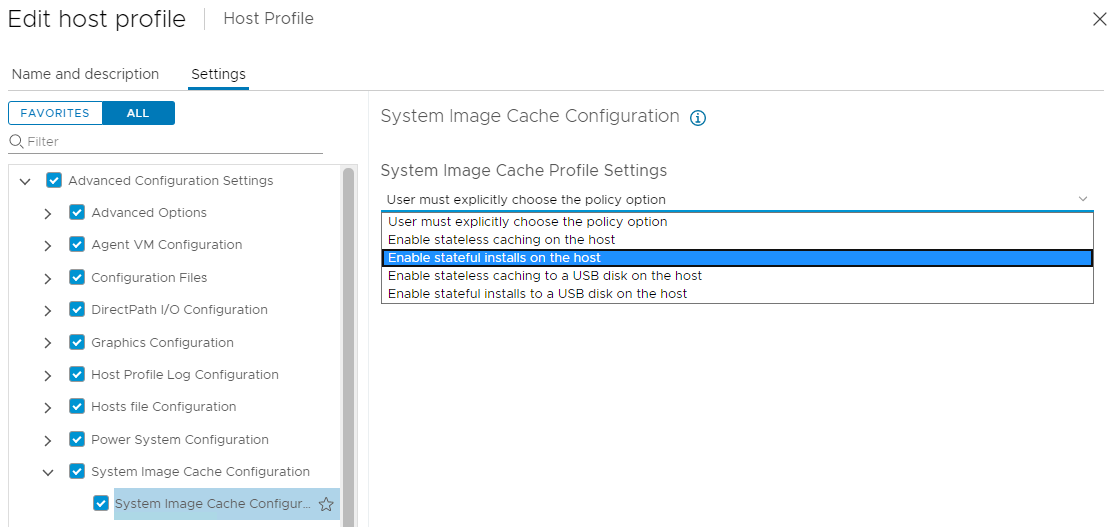
The last big form of isolation is network segmentation. At a very basic level you can add additional network interfaces to your ESXi hosts, enabling you to separate management traffic from VM & workload traffic. If you imagine that adding a ton of extra NICs to a server is an unwieldy sort of thing you’d be right, which is why some clever networking folks created the idea of a “virtual LAN” or VLAN. VLANs do to a network link what ESXi does to compute hardware: virtualize it. VLANs are identified by a number, 0 through 4095, which is added to each network frame sent as a “tag” – why you will often hear it referred to as VLAN tagging. On a network switch, each port can be assigned to a single VLAN, or to multiple VLANs in what is known as a “trunk.” On the ESXi side of this you access these trunks by creating port groups and specifying which VLAN you want them to be part of:

Each VLAN can then be assigned its own IP address range, and security controls like firewalls and ACLs can be put in place to separate workloads, desktops, and the internet from the sensitive management interfaces for infrastructure.
What Networks Should I Isolate in a vSphere Deployment?
The VMware Validated Design is the reference architecture for deploying VMware products, and it wisely suggests separating:
- vSphere Management (ESXi & vCenter Server)
- vMotion
- vSAN
- NSX-T endpoint traffic (TEP)
as well as separate VLANs and IP ranges for workloads and applications, too, depending on your security needs (as an aside, if you are compliance-minded the Validated Design has excellent NIST 800-53 and PCI DSS kits, too – check the “Security and Compliance” sections). From there, you can add firewalls and ACLs to help control who is allowed into what services.
VMware is a software company, so it is understandable that we would not make hardware suggestions but based on my own experience I also suggest a separate hardware management VLAN. Servers often have very powerful “out of band” management capabilities that can be used for firmware management, hardware monitoring, and remote console & control, and being able to operate and secure those separately from vSphere is often extremely helpful (even just for troubleshooting). Enabling the out-of-band management capabilities in this way can also help avoid complexities and isolation issues in other ways. For instance, these management controllers can often present a virtual NIC to ESXi, allowing ESXi access to the management controller. Is this a good thing? Every environment is different, but it certainly complicates any isolation between those networks and introduces additional components and configuration to be assessed, managed, and secured.
Security Requires Constant Vigilance
Just over two decades ago Bruce Schneier wrote that “security is a process, not a product.” He is absolutely right, even to this day. VMware has some tremendous tools to help with security, and vSphere is at the core of many of the world’s most secure environments. In the end, though, the biggest boon to an organization’s security is thoughtful people who understand that achieving security is a constant & evolving process, and can wield those powerful tools to help their organizations practice & design for core principles like least privilege and defense in depth.
Stay safe, my friends.
The post The Importance of Isolation for Security appeared first on VMware vSphere Blog.